Claude Fable 5 appears to provide a better performance on tasks than Opus 4.8 for a given cost.
FinTech BizNews Service
Mumbai, 12 June 2026: The latest Kotak Institutional Equities report on IT Services provides useful insights.
Claude Fable 5 increases AI disruption risks for IT services
Anthropic has released Claude Fable 5 model, a better version of the Mythos Preview model announced in April, but with new safeguards to prevent misuse. The new model shows a significant step up in software engineering tasks, which is not a surprise. It does not seem to exhibit a similar capability improvement in other domains. The stronger improvement in software tasks and improvement in agentic software development capability increase revenue deflation risks for IT services firms in the near to medium term, particularly for firms with large exposure to application services. Still, a few factors can constrain widespread enterprise adoption of Claude Fable 5. How enterprises utilize frontier models, given the higher focus on controlling token costs, will be key to watch out for.
Anthropic releases new Claude Fable 5 model
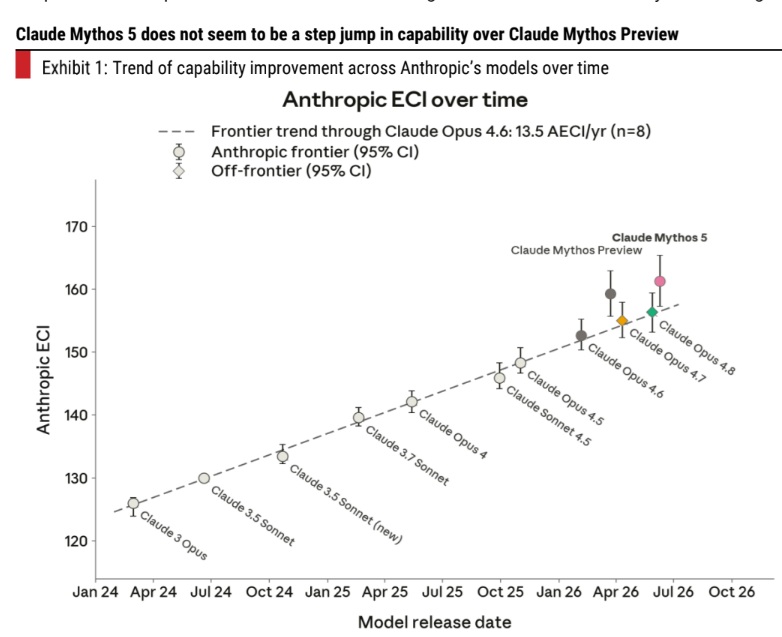
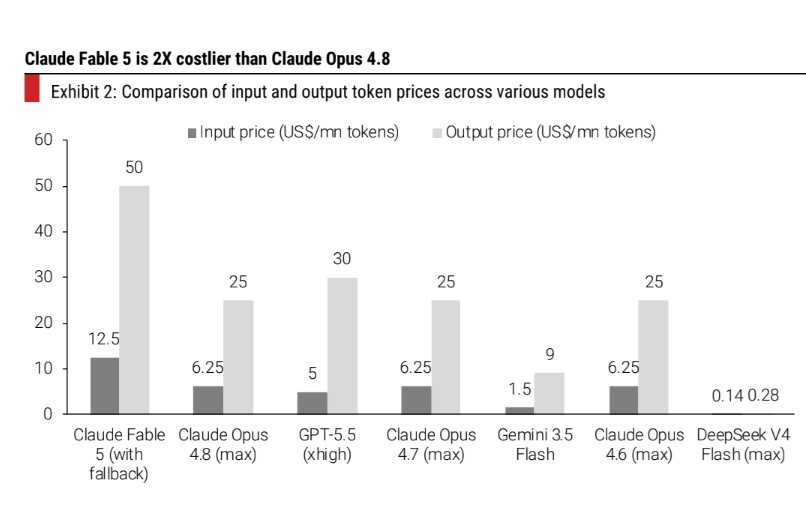
Anthropic has released Claude Fable 5 and Mythos 5 models. Both have better capabilities than the Mythos Preview model announced in April 2026, but not a step jump (Exhibit 1). Fable 5 model is publicly available and is similar to Mythos 5, but has a few guardrails to restrict usage in certain areas. Mythos 5 does not have these guardrails and is available only to select partners. The models have a one million context window. The pricing is 2X of Opus 4.8 and higher than other frontier models’ pricing (Exhibit 2), but ~2-2.5X lower than Mythos Preview. The timing of the model release and pricing are perhaps better than earlier expected.
New model shows a significant step up in software engineering tasks
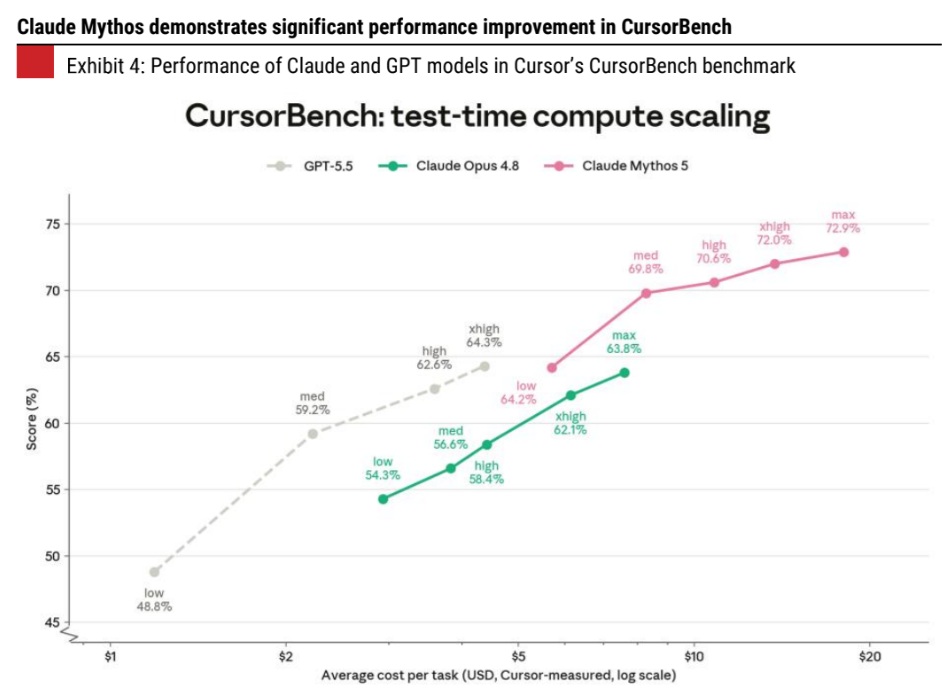
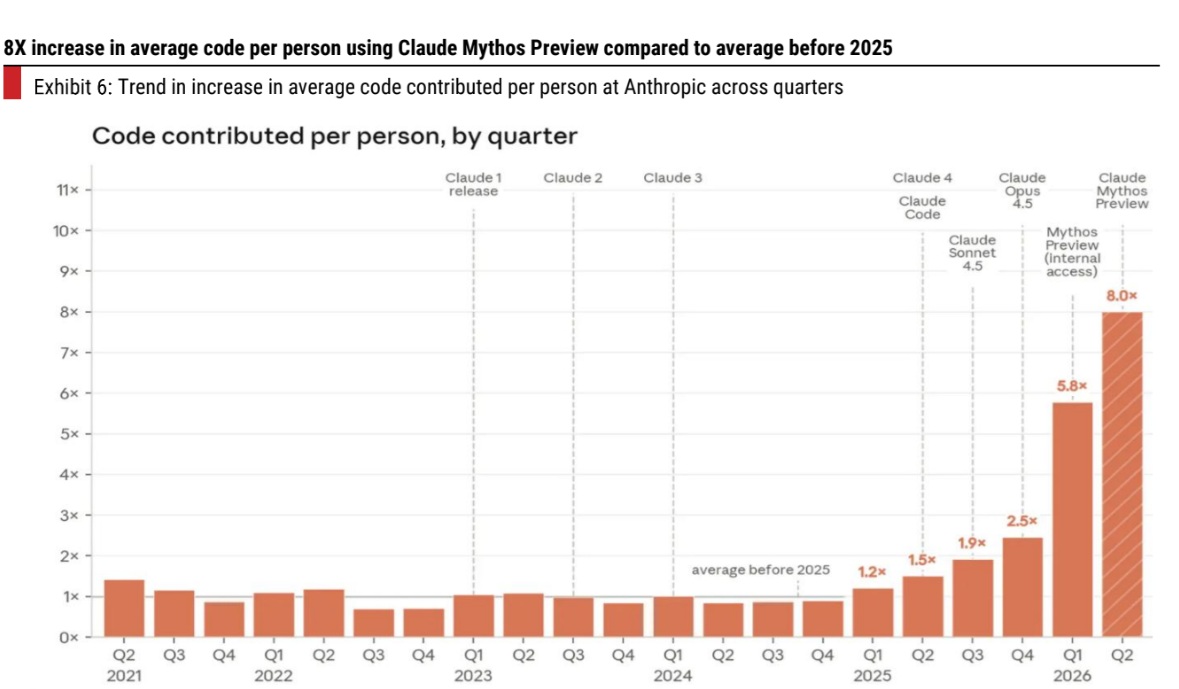
The performance of Claude Fable 5 shows a significant improvement in software engineering tasks based on selected benchmarks and data from Anthropic, which is not a surprise. In SWE Bench Pro (agentic coding), Fable 5 scores 11% higher than Opus 4.8 and 22% higher than GPT 5.5..In Frontier Code (Diamond) (agentic coding), it scores 16% higher than Opus 4.8 and 24% higher than GPT 5.5. METR’s analysis done on the Claude Mythos Preview model estimated that the model could complete 3 hour+ tasks with an 80% success rate, a large jump from previous models.. Anthropic indicated a step jump in average code per person using the Mythos Preview model.. The model’s ability to handle complex problems has improved.. Anthropic also indicated that the quality of code generated by AI—while lower than humans earlier—is now on par with current models. It expects it to be better within the next year.
Does not seem to exhibit similar capability improvement in other domains
Claude Fable 5 shows an increase in capability in tasks in non-software-related domains, which are sometimes significant but sometimes incremental. The overall level of improvement appears to be lower than that in software tasks. In Databricks’ OfficeQA benchmark, Fable 5 scores 10% higher than Opus 4.8, which is significant (Exhibit 9). The performance in Zapier’s AutomationBench seems to demonstrate incremental improvement over previous models. The performance of Claude’s last three models on Vals AI’s benchmarks indicate sharper improvement in performance on coding benchmarks versus finance benchmarks.
Can increase downside risks for IT services firms
We estimate GenAI adoption by enterprises to impact revenues by 3-3.5% annually over the next three years for IT services firms. We expect tailwinds from GenAI adoption in business use cases to offset deflation in IT services after three years. Differential model capability improvement in software and non-software-related tasks, together with what appears to be faster pace of improvement in software tasks than expected, can increase AI disruption risks for IT services firms.
We expect Mythos 5/Fable 5 to increase efficiencies across all IT services segments. Yet, stronger agentic software engineering capabilities could result in a widening of the gap in productivity increase between application services (also called application development and maintenance) and other IT services segments (including BPO). Among Tier 1 Indian IT, Infosys has a higher exposure to applications, while HCLT has a lower exposure. In general, mid-tier IT has a higher exposure to applications, with Persistent leading the pack among the Indian names. Mid-tier challengers can offset headwinds by share gains from slow-to-adapt incumbents.
A few factors can constrain widespread enterprise adoption of Claude Fable 5
The release of latest Claude models comes with a few factors that can limit adoption. We briefly discuss them below:
4 | Fable 5 has been equipped with safeguards. This is for preventing misuse and can lead to the model erring on the side of caution. Fable 5 has separate AI systems that detect potential misuse, including jailbreak attempts and prevent the main model from responding. Queries on some topics will receive a response from Claude Opus 4.8 instead. The following are the areas covered by the AI systems— (1) cybersecurity, (2) biology and chemistry and (3) model distillation attempts. These safeguards can impact quality of responses from Fable 5. |
4 | Fable 5 has features to limit its usage to develop frontier LLMs. Anthropic has implemented new interventions that limit Claude’s effectiveness for requests targeting frontier LLM development. Unlike interventions for cybersecurity, biology and chemistry and distillation attempts, these safeguards will not be visible to the user. |
4 | New data retention policy. Anthropic has made a change to the way it will handle business customer data for Fable 5 and Mythos 5, which will extend to future models with similar or higher capability levels. The company requires a 30-day retention for all traffic on Mythos-class models. Anthropic will not use this data to train new Claude models, or for any non-safety-related purpose. The data will be used to defend against complex and novel attacks as well as help Anthropic identify and reduce false positives. Enterprises may not be willing to share data with Anthropic. |
4 | Transition to fully token consumption-based pricing. Fable 5 is currently included on Pro, Max, Team and seat-based Enterprise plans at no extra cost. However, from June 23, Fable 5 will be removed from these plans and usage of the models will require usage credits. Anthropic can extend the timelines based on availability of compute and will aim to restore Fable 5 as a standard part of subscription plans once sufficient compute capacity is available. |
How enterprises utilize frontier models given focus on token costs will be key to watch out for
Claude Fable 5 appears to provide a better performance on tasks than Opus 4.8 for a given cost. Exhibit 8 provides an example. Anthropic is guiding users to shift from prompting and steering to building loops where the model can work autonomously to provide the output with lesser human intervention. The emphasis is also to use model versions with higher reasoning effort, which will consume more tokens but provide better output. The pricing is shifting to more consumption-based billing. Together, these serve to increase token costs for users.
Enterprises are now taking more stringent steps to control token costs. They will have to decide whether using frontier models with high reasoning effort that promises greater accuracy and autonomy but higher token costs is better compared to using cheaper models or lower reasoning effort. Anthropic would want enterprises to choose the former. Such a scenario can lead to higher spend on tokens which can cut into budgets for other areas such as IT services. We believe that enterprises will want to spend less tokens on easy tasks and spend more on complex tasks as a compromise.
Not all benchmarks show a step up in performance versus existing frontier models
Most benchmarks show a significant progress from Opus 4.6 (the state-of-the-art model when Mythos Preview was announced in April) to Fable 5. However, the magnitude of progress in select benchmarks is not significantly greater relative to frontier models of peers. In Artificial Analysis Intelligence Index (weighted average of scored across multiple benchmarks), Fable 5 scores 65 compared to GPT 5.5, which scores 60.2. Opus 4.6 scored 52.9. In the Terminal-Bench Hard benchmark (tasks in computer terminal environments) Fable 5 scores 63, not too different from GPT 5.5’s score of 61. Opus 4.6 scored 46.
Enterprises are already indicating step change in productivity expectations in software development
As discussed in our earlier note on tech trends in the BFS vertical, select BFS firms are indicating large productivity improvements in software development, likely driven by agentic software development. If what Anthropic indicates in terms of average code per person is true, i.e., Fable 5 turns out to be another inflection point in agentic software development similar to the Opus 4.5 model then the productivity expectations of enterprises will only increase further. This could lead to higher revenue deflation for IT services firms if existing volumes of work do not expand.
Deflation could be compensated by higher software volumes. This can be facilitated if enterprises opt for more ‘build’ versus ‘buy’. Yet, the commentary from select BFS firms indicates that they do not expect to replace third-party software providers with custom software. In fact, they expect to use AI functionalities, that will be embedded in third party software.
Legacy modernization is another area of work that will be accelerated by AI and could drive new opportunities for IT services. However, AI seems to be able to manage a bulk of the modernization effort. For example, Stripe indicated that using Fable 5 it was able to migrate 50 mn lines of Ruby code in a single day, which would have taken two months without AI. We do not know if such productivity increases are possible in complex brownfield environments though where IT services firms may have the edge.